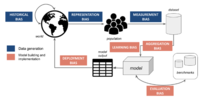
This paper explains the potential biases that may arise throughout the lifecycle of artificial intelligence systems, taking an iterative approach to the processes of data generation, model development, and deployment.
We provide a definition of the typical issues associated with each stage and a specific mitigation strategy.